
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 앱 비교 프로젝트
- 애플 아카데미 후기
- 네이버 치지직
- 신입 개발자
- 신입 ios 개발자
- swift문법
- iOS 개발 오류
- 숭실대
- 애플 디벨로퍼 아카데미 후기
- sqoop
- Swift 기능
- 소프트웨어분석및설계
- 애플 디벨로퍼 아카데미 21주차 회고
- OS
- Swift 디자인패턴
- 데이터베이스
- 네이버 부스트캠프
- 운영체제
- 개발회고
- Swift 문법
- react
- ios개발자
- 제앱소
- 애플 디벨로퍼 아카데미
- 신입ios개발자회고
- 개발자 회고
- Apple Developer Academy @ POSTECH
- apple developer academy 후기
- SWIFT
- global soop
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 앱 비교 프로젝트
- 애플 아카데미 후기
- 네이버 치지직
- 신입 개발자
- 신입 ios 개발자
- swift문법
- iOS 개발 오류
- 숭실대
- 애플 디벨로퍼 아카데미 후기
- sqoop
- Swift 기능
- 소프트웨어분석및설계
- 애플 디벨로퍼 아카데미 21주차 회고
- OS
- Swift 디자인패턴
- 데이터베이스
- 네이버 부스트캠프
- 운영체제
- 개발회고
- Swift 문법
- react
- ios개발자
- 제앱소
- 애플 디벨로퍼 아카데미
- 신입ios개발자회고
- 개발자 회고
- Apple Developer Academy @ POSTECH
- apple developer academy 후기
- SWIFT
- global soop
- Today
- Total
사과하는 제라스
2. 동시성 제어(Concurrency Control) 본문
목차
현재까지 나와있는 동시성 제어 방법 중 Locking이 가장 효율적인 방법이기에 현재 가장 많은 DBMS에서 쓰인다.
∴ Locking 방법만 찾아볼 거임.
2.1. 록 기반 규약(Lock-based Protocols)
Lock: 데이터 아이템에 대한 동시성 접근을 다루기 위한 메커니즘.
Locking Protocol: 모든 트랜잭션이 Lock을 Requesting, releasing 을 할 때 따르는 규약들.
-> 이 프로토콜을 씀으로서 가능한 스케쥴 세트를 제한함.
데이터 아이템은 두가지 방식으로 Lock 될 수 있음.
1) Exclusive mode(=Write Lock): 데이터 아이템은 Read/Write 가능(Write가 필수는 아님), 주로 lock-X instruction 사용, 다른 Lock 모드와 호환성이 없음(Why? 다음 표 참조).
2) Shared mode(=Read Lock): 데이터 아이템은 Read 가능, 주로 lock-S instruction 사용
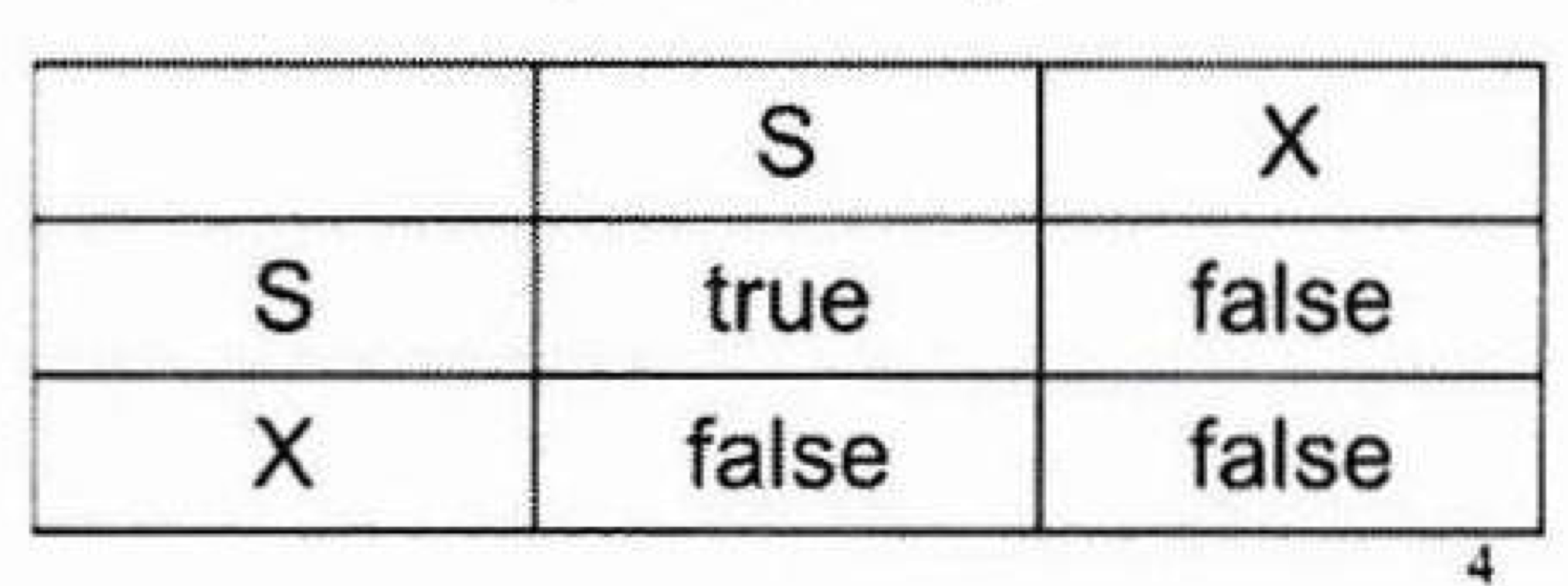
트랜잭션은 request가 granted(승인)되었을 때 진행될 수 있다.
트랜잭션이 Write하려면 Write Lock을, Read하려면 Read Lock을 받아와야만 진행할 수 있다.
-> 이때, Share mode인 경우엔 만약 내가 부여 받고자 하는 Lock도 그러하다면 받을 수 있으나 나머지 경우(Incompatible Lock, 호환성이 없는 Lock 관계)는 충돌 Lock으로 인지됨.
∴ 이때 다른 트랜잭션에 부여된 충돌 Lock으로 인해 데이터에 대한 Lock을 기다리는 트랜잭션은 그 충돌 Lock이 해제될 때까지 기다린 후 해당 데이터에 대한 Lock을 부여 받아 진행함.
즉, Read Lock은 동시에 다수의 트랜잭션에게 부여할 수 있으나, Write Lock은 반드시 1개의 트랜잭션에만 부여할 수 있음.

위 예시에서는 Locking이 Serializability를 보장하지 않는다! 왜...?!!!
-> 만약 위에서 unlock(A)를 했어. 근데 다른 트랜잭션에서 만약 A나 B의 값을 변경해버려. 그럼 A+B의 값은 바뀌잖아~
∴ 추가적인 록 규약이 더 필요함! 그게 Two-phased Locking Protocol임.
Two-phased Locking Protocol(2PL)
Phase 1: growing phase
: Lock을 얻는 단계로 Lock을 풀 수 없다.
Phase 2: shrinking phase
: Lock을 푸는 단계로 Lock을 얻을 수 없다.
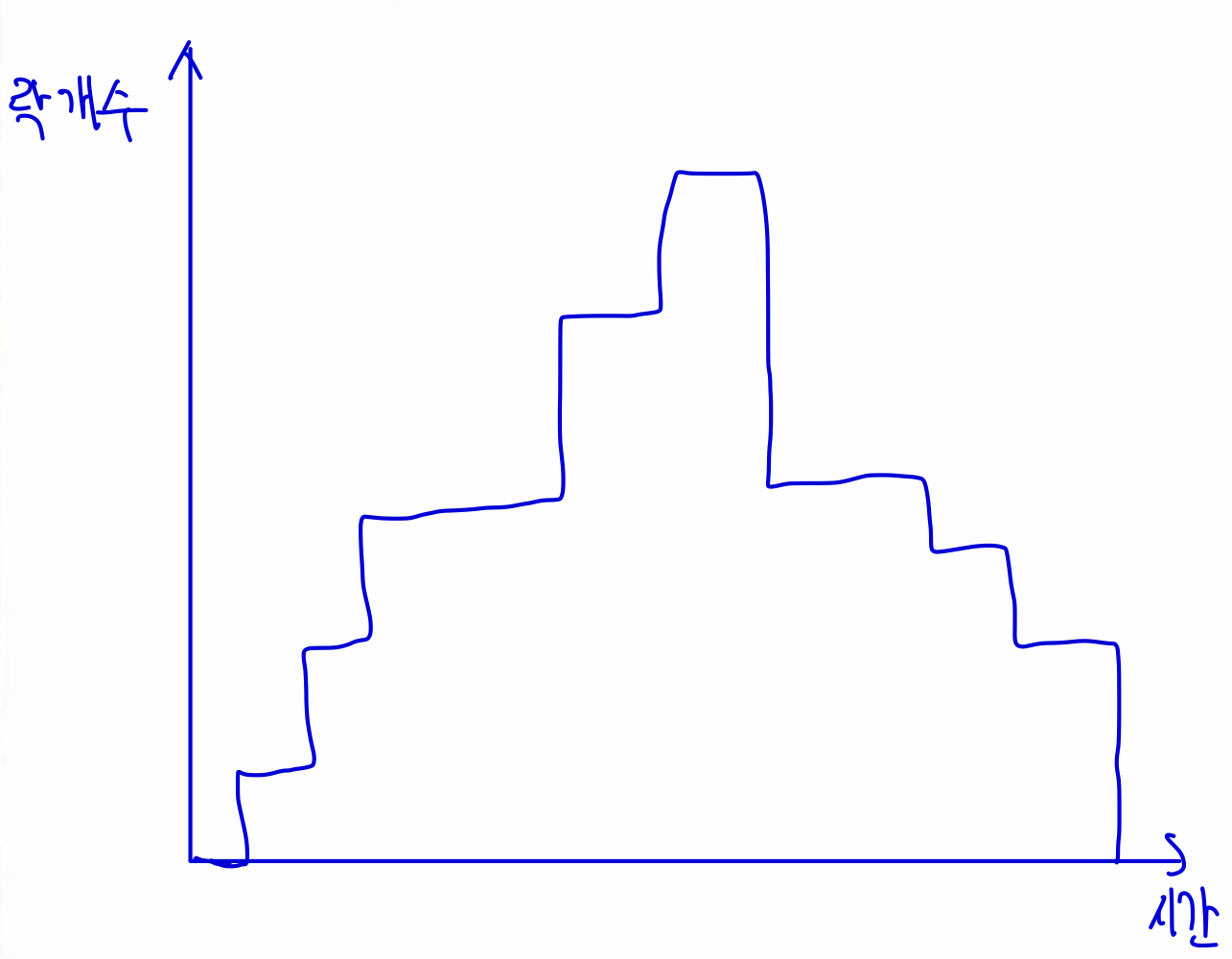
-> 이 2PL까지 만족하면 Serializability는 보장된다.(충돌 직렬 스케줄 제공을 보장한다.)
하지만, 2PL을 이용하여 모든 충돌 직렬가능 스케줄을 생성하는 것은 아니고, 2PL이 생성하지 못하는 충돌 직렬가능 스케줄도 존재한다.
이에 대한 설명은 아래 그림으로 설명한다.
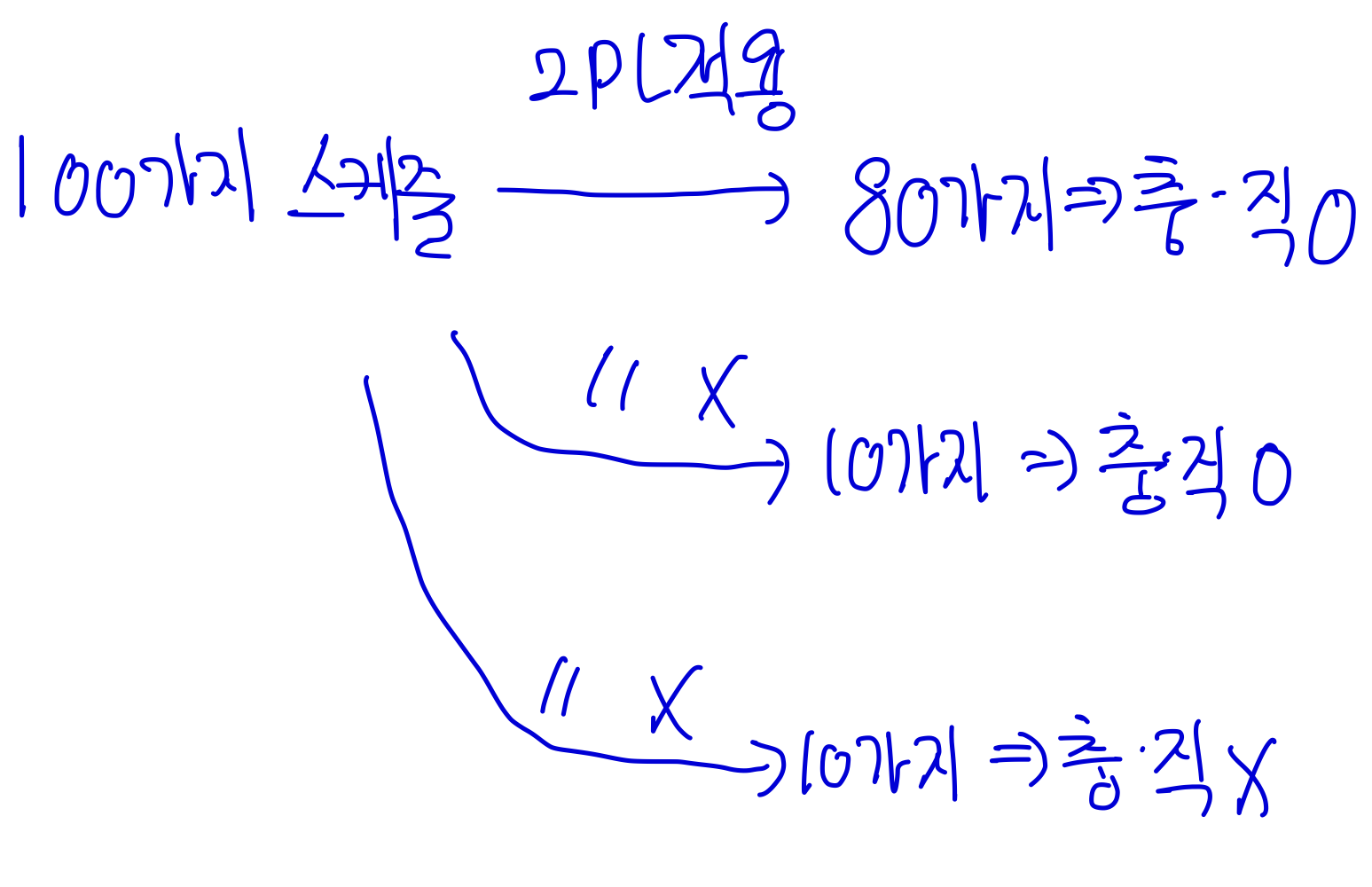
- 2PL은 트랜잭션 중간에 unlock 가능하기에 연속철회 스케줄을 만들 수도 있다.
이를 방지하기 위해 strict, rigorous 2PL 방식이 생겨났다.
1) strict 2PL
: 트랜잭션이 종료할 때까지 Write Lock(X-Lock)을 보유(Read Lock은 허용)하는 방식
-> 트랜잭션이 commit/abort된 것만 읽을 수 있게 하여 데이터를 쓴 트랜잭션이 Lock이 중간에 풀리지 않도록 방지.
2) rigorous 2PL
: 트랜잭션이 종료할 때까지 Write Lock, Read Lock 모두 보유하는 방식
- 2PL은 deadlock이 항상 나옴.(Locking 기술을 사용하면 deadlock은 항상 나온다!)
2PL Lock Conversion
2PL에서는 Lock에 대한 모드를 변경할 수 있음.
단, growing phase에선 lock-S를 lock-X로 바꾸는 upgrade만 허용하고
shrinking phase에선 lock-X를 lock-S로 바꾸는 downgrade만 허용함.
왜 2PL은 충돌 직렬 가능 스케줄만은 생성할까?
반대로 생성할 수 없다고 가정하자.
T0->Tm->...Tn->T0로 사이클이 존재한다고 가정하자.
일단 2PL의 정의에 의해
Ti<Tj이면 ai<aj이다.
이때 그렇다면 위 가정에서 시간은 a0<am<...<an<a0이고
a0<a0인 모순이 생기기에 사이클이 생길 수 없다.
∴2PL은 충돌 직렬 가능 스케줄만을 생성한다.
Lock을 시스템 내부적으로 어떻게 구현?
Lock 담당 프로세스를 독립적으로 구성될 수 있다.
이 Lock을 담당하는 매니저는 내부적으로 lock table을 관리하면서 Lock 처리를 수행함.
-> Lock manager가 메인메모리에 lock table 데이터 구조로 저장하고 관리한다. 이때 빠른 접근을 위해 데이터 항목 이름을 해쉬 색인을 해둔다.
Lock Table
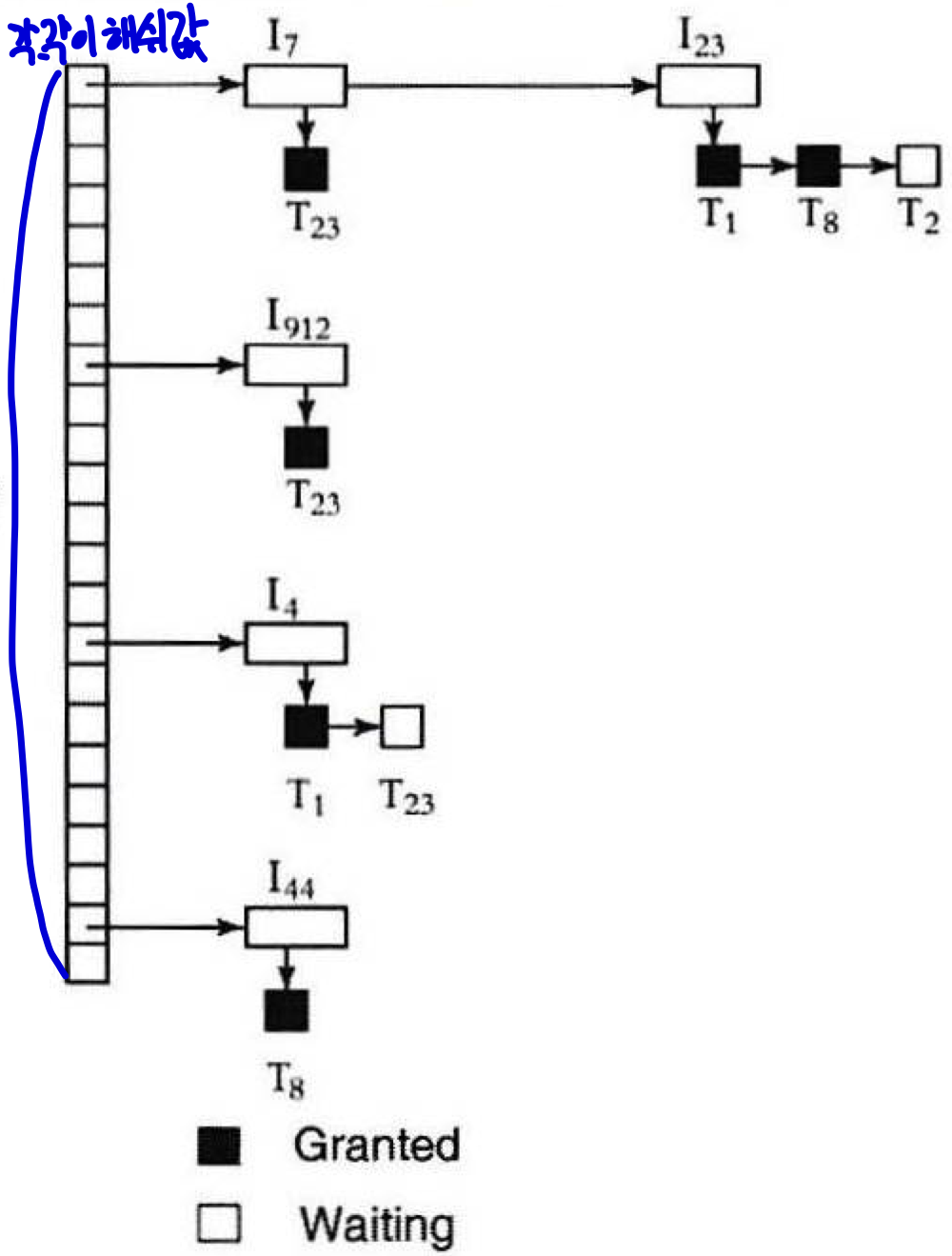
<테이블 설명>
- 데이터 항목 I7, I23은 동일 해쉬 값을 갖고 있음.
- I23에서 T1, T8은 Write Lock 허용 but, T2는 Read Lock까지만 허용됨.
- T23은 데이터 항목 I7, I912에 대한 Lock만 갖고 있고 I4에 대해서는 Lock을 기다리는 중임.
Deadlock(교착상태)
: 트랜잭션이 서로에게 Lock을 요청하면서 무한정 대기상태에 빠지는 것. Lock을 기반으로 하는 모든 상황에서 무조건 발생함.
-> Deadlock 상태에 있는 트랜잭션은 다른 데이터에 대한 Lock을 가지고 있는 경우가 많기에 DBMS 전체의 정지상태를 발생시킬 수 있다. 이는 OS에서도 프로세스에 대한 자원분배 상황에 발생한다.
Starvation(기아상태)
: 특정 트랜잭션이 Lock을 획득하지 못한 채 필요 이상으로 Lock을 기다리는 현상. 이는 Lock manager의 Lock 배분 정책의 잘못으로 발생함.
ex1) 어떤 데이터 항목에 대한 Write Lock을 트랜잭션 A가 기다리고 있음, 하지만 다른 트랜잭션들이 Read Lock을 요청했기에 허용해줌. -> A의 순서가 계속 밀리게 됨.
ex2) 같은 트랜잭션이 반복되는데 deadlock에 의해서 계속 rollback됨.
∴ deadlock은 발생할 수 있지만, starvation은 반드시 피해야 한다!
Graph-based Protocol
Tree-based Protocol의 기본이 되는 규약으로, 데이터에 부분 순서가 존재하고 이 순서대로 접근을 해야하는 규약.
-> 실질적으로 일반 데이터에 적용하기에는 불가능함.
그래서 쓰는게...!!
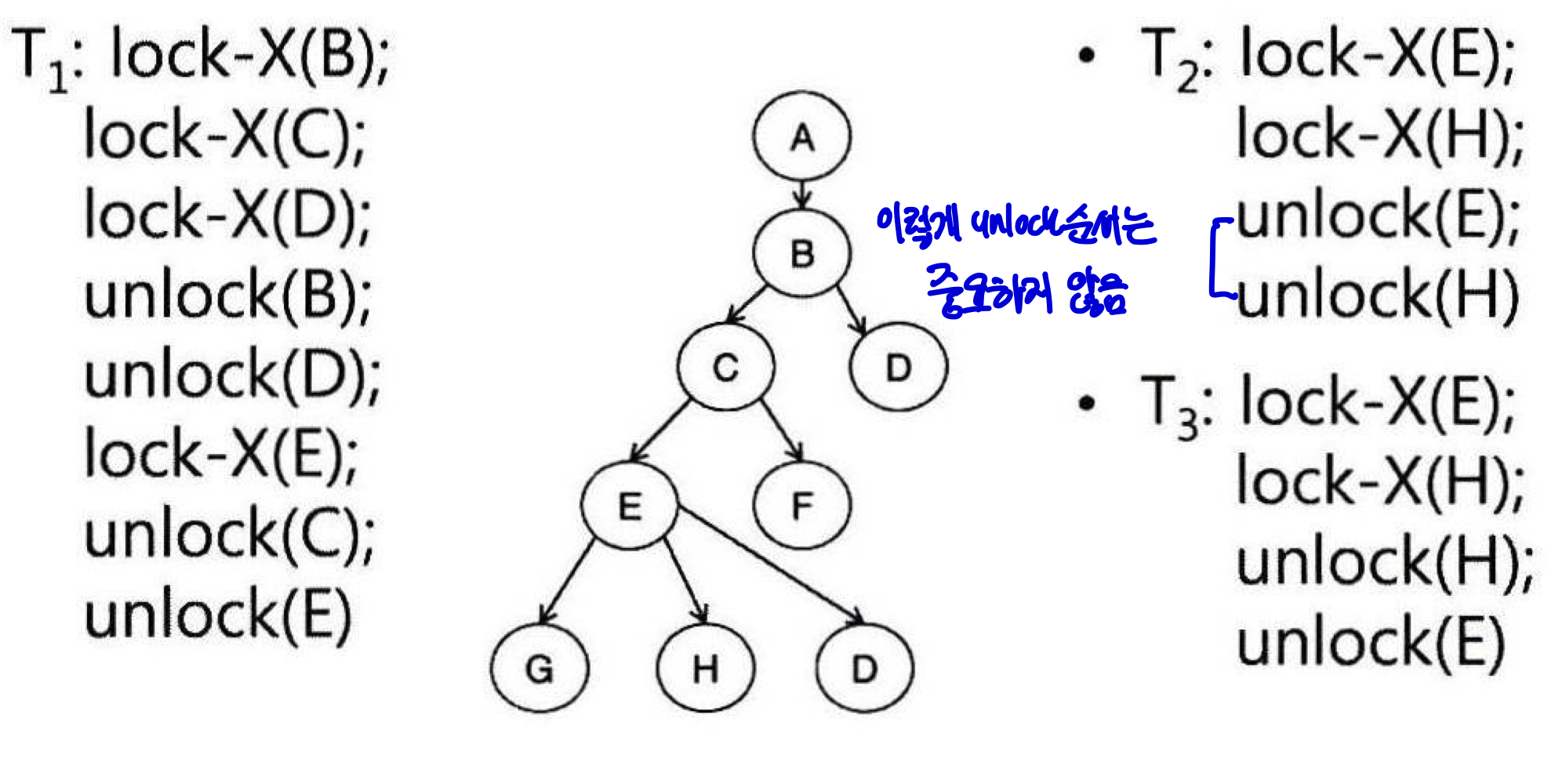
Tree-based Protocol
: 그래프 기반 규약에서 비롯된 방식으로 unlock이 제약없이 가능하고 unlock 뒤에 lock 요구가 가능한 규약. 이때 획득했던 lock은 해제 후 다시 잡을 수 없음.
<특징>
1) X-lock만 허용됨.
2) 첫 lock은 아무곳에서 가능함.
3) 부모가 lock을 부여받아야 자식도 lock될 수 있음.
4) unlock은 아무때나 가능함.
장점:
1. 충돌 직렬 가능을 보장함.
2. unlocking에 제한이 없기에 2PL보다 짧은 대기 시간 -> 동시성 향상
데이터 간에 순서를 정하여 한쪽 방향으로만 request를 허용하므로 임의 데이터에 대한 lock을 가지고서 타 데이터 lock을 기다리는 deadlock이 발생하지 않는다.+ rollback이 요청되지 않는다.
단점:
1) 회복가능성이 보장이 안 되고 연속철회가 발생할 수 있음.
2) 접근하지 않는 데이터 항목들도 lock을 해줘야 함. -> 추가 대기 시간-> 동시성 저하
3) 데이터 간에 순서가 있을 때 사용해야 함.
지금까지는 Lock을 거는 모드에 대한 얘기를 했다! 이제는 어떤 것에 Lock을 거는 것인지 알아보자...!!
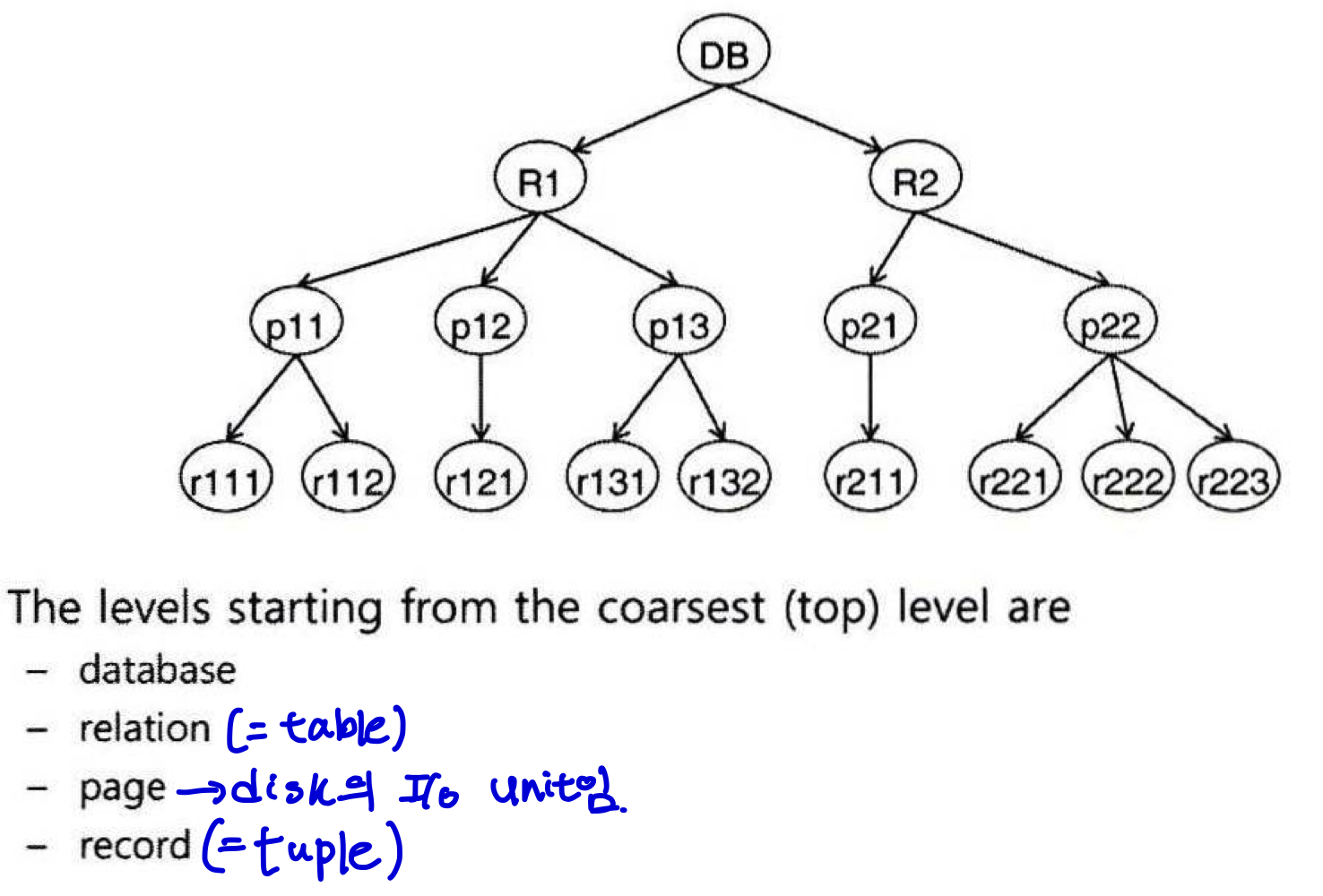
2.2. 다중 단위 크기 록킹(Multiple Granularity Locking, MGL)
: DBMS가 locking이 적용되는 데이터 크기를 다양하게 지원하는 것.
어떤 노드에 대해서 explicit하게 lock을 걸면 그 하위 노드들에 대해서도 implicit하게 lock을 걸게 된다.
데이터의 크기가 작은면 동시성은 좋아지나, Locking 오버헤드가 커짐.
반대로, 데이터의 크기가 크면 동시성은 낮아지지만, Locking 오버헤드가 작아짐.
∴ Multiple Granularity Locking을 통해 적절히 섞어서 사용한다.
의도 록 모드(Intention Lock Modes)
S: 해당 노드에 Read Lock 검.
X: 해당 노드에 Write Lock 검.
IS: 해당 노드의 하위 노드 중 하나에 Read Lock을 검.
IX: 해당 노드의 하위 노드 중 하나에 Write Lock을 검.
SIX: 해당 노드 전체에 Read Lock 걸고, 그 중 일부 데이터에 대하여 후에 Write Lock을 검.
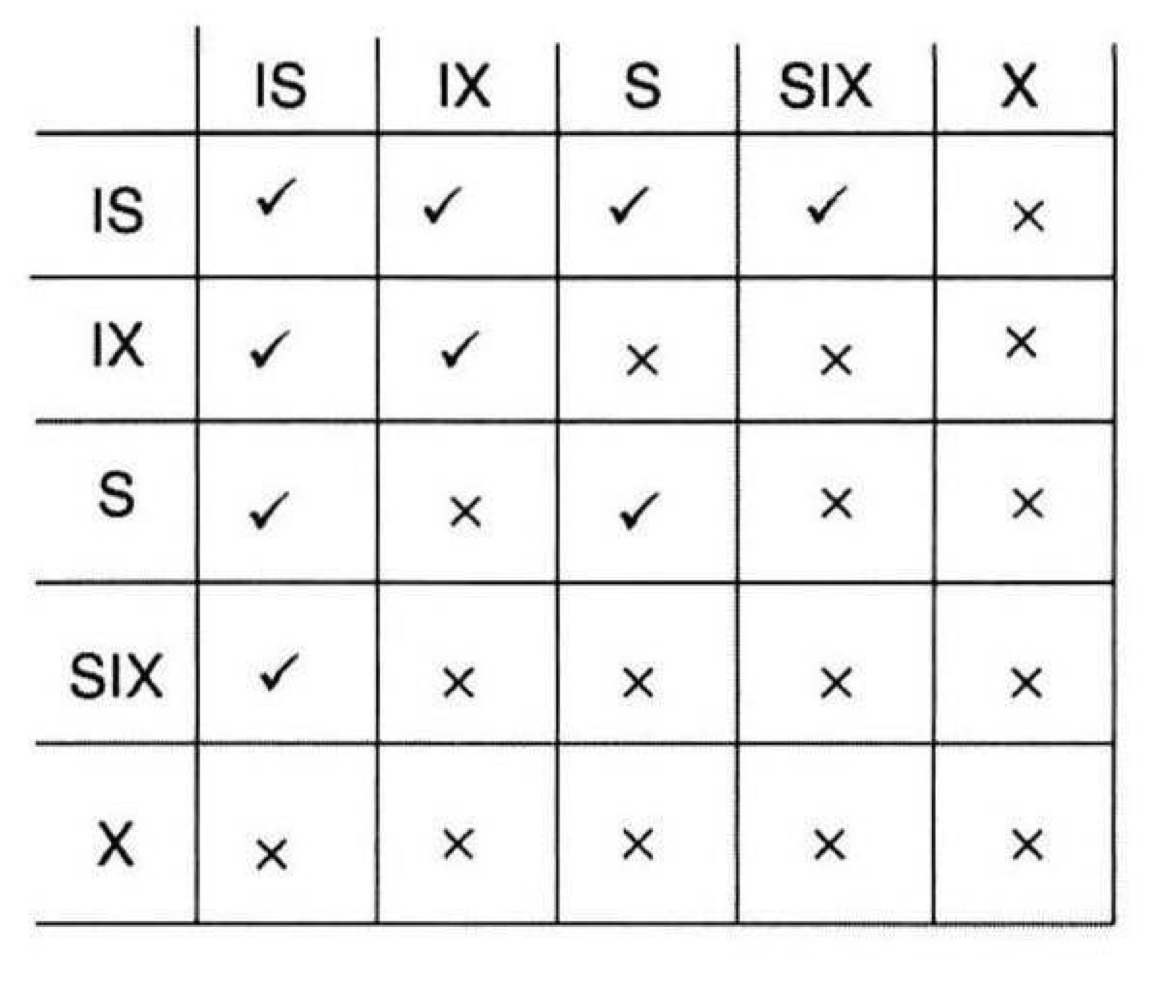
IS-IS: 현재 노드와 상관없고, 하위 노드에서 S가 겹쳐도 S와 S는 호환되니 괜찮음.(O)
IS-IX: 현재 노드에서는 상관없고, 하위 노드에서 S와 X가 겹치면 그건 거기 노드에서의 문제니 상관없음.(O)
IS-S: 현재 노드에선 겹치지 않으니 상관없고, 하위 노드에서 S가 겹쳐도 호환되니 괜찮음.(O)
IS-SIX: 현재 노드에선 겹치지 않으니 상관없고, 하위 노드에서 S와 X가 겹치면 그건 거기 노드에서의 문제니 상관없음.(O)
IS-X: 현재 노드에선 겹치지 않으니 상관없지만, 하위 노드에서 S와 X가 반드시 겹치므로 안됨.
IX-IX: 현재 노드에서는 상관없고, 하위 노드에서 X와 X가 겹치면 그건 거기 노드에서의 문제니 상관없음.(O)
IX-S: 현재 노드에서는 상관없지만, 하위 노드에서 S와 X가 반드시 겹치므로 안됨.
IX-SIX: 현재 노드에서는 상관없지만, 하위 노드에서 S와 X가 반드시 겹치므로 안됨.
IX-X: 현재 노드에서는 상관없지만, 하위 노드에서 X와 X가 반드시 겹치므로 안됨.
S-S: S와 S는 겹쳐도 전혀 문제없음.(O)
S-SIX: 현재 노드에서는 S와 S가 겹쳐도 상관없지만, 하위 노드에서는 S와 X가 반드시 겹치므로 안됨.
S-X: 현재 노드에서 S와 X가 겹치므로 안됨.
SIX-SIX: 현재 노드에선 S와 S가 겹치므로 상관없지만, 하위 노드에서는 S와 X가 반드시 겹치므로 안됨.
SIX-X: 현재 노드에서 S와 X가 겹치므로 안됨.+ 하위에서도 무조건 겹치므로 안됨.
X-X: 현재 노드에서부터 X와 X가 겹치므로 안됨.
MGL의 특성
1) 반드시 Lock 호환성을 만족해야 함.
2) 트리의 root는 반드시 제일 먼저 Lock되어야 함.
3) Locking은 root -> leaf 순으로, Unlocking은 leaf -> root 순으로 되어야 함.
2.3. Deadlock(교착 상태)
- lock을 기반으로 하는 자원을 경쟁적으로 사용하려는 lock-based 스케줄에서 항상 등장함.
어떤 스케줄 내의 모든 트랜잭션들이 다른 트랜잭션을 기다리는 경우 시스템은 Deadlock이다.

Deadlock 처리방식
1) 타임 아웃 방식
: 일정 시간 이상 트랜잭션이 lock을 기다리지 않게 하는 방식. 트랜잭션이 일정 시간을 기다리고 그래도 lock이 안풀리면 roll back 함.
-> DB의 정확한 상태 정보를 수집하기 어려운 환경에서 사용.
2) 교착상태 방지 방식
: deadlock을 발생하지 않게 하는 방식으로, Graph-based Locking Protocol을 사용함.
3) 교착상태 감지 및 해결 방식
: Wait-die 기법 / Wound-wait 기법
Wait-die 기법: 만약 트랜잭션 A가 기존 트랜잭션과 lock 충돌이 나면 만약 A가 기존 트랜잭션에 비해 old하면 wait, young하면 die하는 방식.
Wound-wait 기법: 만약 트랜잭션 A가 기존 트랜잭션과 lock 충돌이 나면 만약 A가 기존 트랜잭션에 비해 old하면 wound, young하면 wait하는 방식.
-> old한 트랜잭션이 유리하며 재시동 시 기존 time-stamp를 가지고서 재시동을 해야 한다.(기아 상태가 발생할 수 있기 때문!)
교착 상태 감지 방법
: Wait-for graph
G=(V, E)
(V는 vertices의 약자로 시스템에 있는 모든 트랜잭션을 의미함. E는 Edges의 약자로 모든 Ti가 Tj를 기다리고 있다면 Ti-> Tj로 표현하는데 이런게 Edge다.)
이런 방식으로 Wait-for graph를 그렸을 때 사이클이 존재하면 Deadlock(교착 상태)이다.
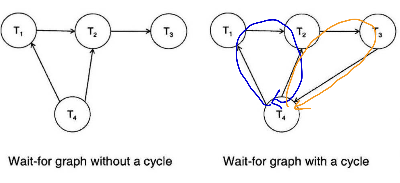
그럼 이렇게 했는데 사이클이 발생(교착 상태가 감지)되면 어쩔 건데...!?
-> 해당 사이클에 있는 몇몇 트랜잭션을 Roll back 시켜서 교착 상태를 깨버려야 함.(이때, 롤백되는 트랜잭션을 Victim(희생자)이라 함)
- Victim으로 선정하는 기준은 롤백 시 가장 적은 비용이 드는 것을 고름.(근데 이거 사실 쉽지 않음...ㅠㅠㅠ)
Total rollback: Victim을 전체 다 롤백하는 방식
Partial rollback: Victim을 일부만 롤백하는 방식(deadlock을 깨는데 필수적인 트랜잭션만 롤백하는 방식임)
근데...계속 같은 트랜잭션만 Victim으로 선정돼서 롤백되면 Starvation이 발생.
근데! 사실 Lock wait는 흔히 일어나지 않음. 근데 deadlock은 더욱 더 흔치 않음.
2.4. 입력 및 삭제 연산(Insert / Delete)
- DB에 새로운 tuple의 Insert, Delete가 빈번히 일어남.
- Insert, Delete되는 tuple은 X-mode lock을 가지고서 수행돼야 함. 이때 팬텀 현상(phantom phenomenon)이 일어날 수 있음.
팬텀 현상(phantom phenomenon)
: Insert/Delete 되는 tuple이 의미적으로 타 트랜잭션이 수행하는 데이터와 관련이 있으면 지연되겠지만, tuple locking을 하는 경우엔 이를 인식하지 못하는 현상. 즉, 서로 다른 item 에 대한 연산을 하지만 그 연산하는 데이터 간에는 연관이 있는데 이를 인지하지 못하기에 충돌이 발생하는 현상.
한번 예시를 보자!


위 예시에서 보면 마지막 T1의 연산 결과는 2200인데 맨 처음 T1의 읽기 연산에서는 1500이 나와야 한다고 생각하고 일치하지 않는다고 판단하게 된다!
이를 방지하는 방법은 뭔데...!?
-> tuple이 아니라 table에 locking을 거는 방법. 이렇게 되면 위 예시에서는 T2가 T1의 unlock을 기다리게 됨.(Table 자체에 대한 lock이기에 T1의 Read Lock에 대해서 Insert 작업(Write Lock)도 제한되어버리니까)
근데!!!!!! 이 table locking은 Concurrency가 매우 떨어지는 방식임!
∵ tuple 하나 Read or Write하는데 Table 전체에 lock을 건다? 이건 혼자 모든 데이터를 다 쓰겠다는 방식이기에 문제가 있음.
그래서 사용하는 방식이 index locking!
table에는 index가 하나씩 생성되어 있음. 이때 트랜잭션 A가 어떤 table의 index에 대한 Read lock을 갖고 있으면 다른 트랜잭션들은 tuple을 쓰려면 색인을 변경해야 하는데 색인에 대한 Write 접근이 불가능하기에 Insert나 Delete가 불가능하다.
index locking에 대한 방법
1) 2PL로 걸기
: lock을 획득하면 트랜잭션의 끝까지 lock을 유지하는 방식이기에 시스템 성능상 Concurrency가 떨어지기에 비효율적임.
그림으로 설명하자면...! index에 lock을 걸면 아래 그림처럼 지나가는 index들에 대한 노드에 대해 lock을 걸게 됨.
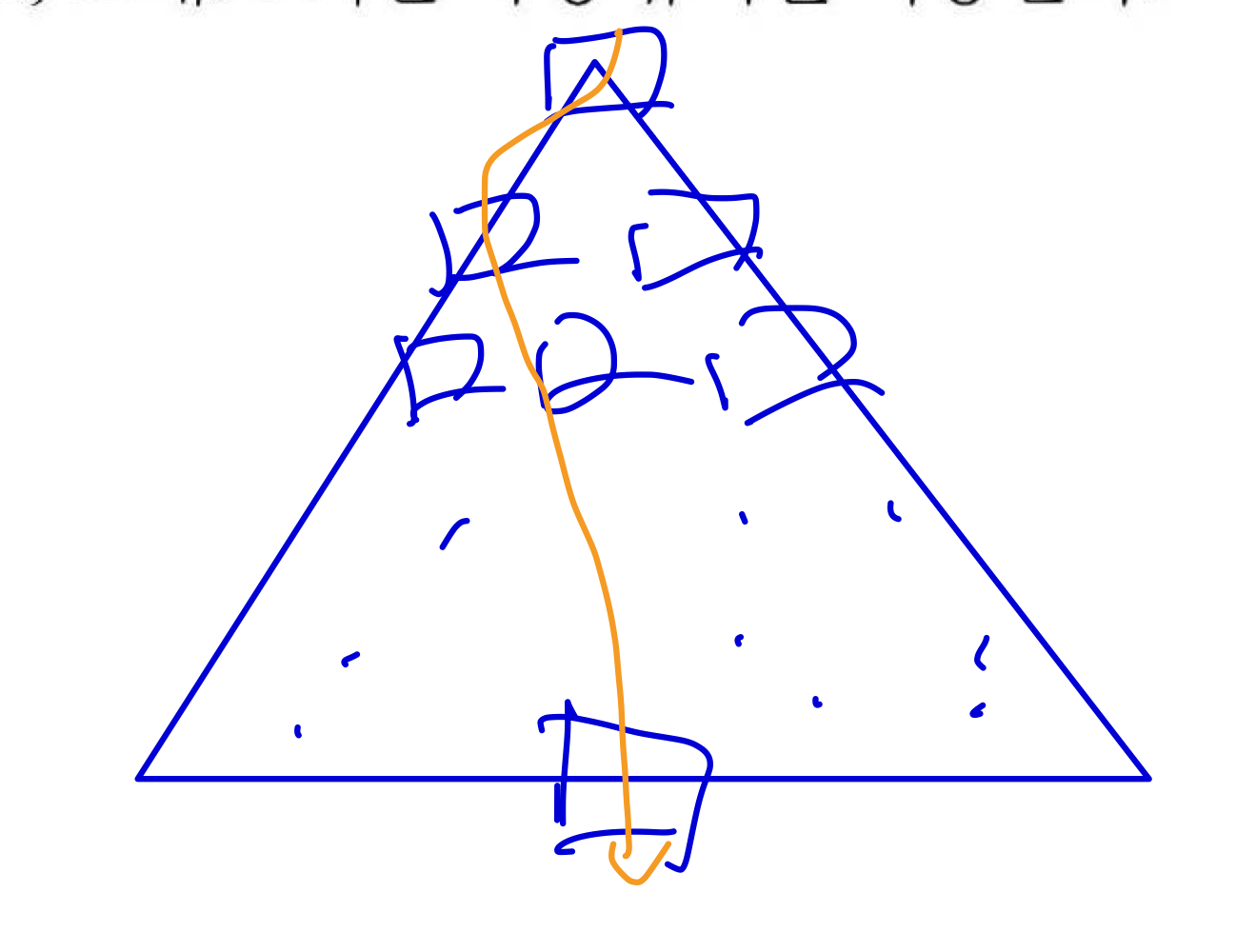
∴ 미리 lock을 푸는 방법이 없을까? 할 때 생각난게 tree-based lock 방식!!
2) Crabbing(이게 tree-based lock 방식)
: root 노드에 대해 lock을 잡고 자식 노드에 대한 lock을 잡고 부모 노드에 대한 lock을 풀고 이를 반복하면서 점차 내려가서 목표하는 노드에 대한 작업을 수행하는 것인데...
문제점: lock이 해제된 부모 노드에 대해 작업을 더 해야할게 생기면 다시 잡게 되는데 이때 위에서 내려오던 locking 작업과 겹쳐져서 Deadlock이 발생할 수 있음.
이렇게 둘 다 문제인데 어떡하지??? *100..
-> 근데 사실 상용 시스템에서는 index locking에서 직렬가능하지 않은 접근도 허용함.
latch라는 것을 활용하여 배타적인 수행을 보장함.
2.5. SQL 트랜잭션 고립(isolation)
- SQL에서는 DML 문장이 나오면 트랜잭션이 implicit하게 실행이 되고(즉, 알아서 실행된다는 거임.),
commit work(트랜잭션의 성공적인 종료)나 rollback work(트랜잭션의 실패에 의한 종료) 문장으로 끝남.
- auto commit 기능이 활성화 되어 있다면, SQL 문장들은 각각이 하나씩 트랜잭션으로 구성됨.

savepoint: 트랜잭션 철회 시 트랜잭션의 처음까지 롤백하지 않고 savepoint된 시점까지로 롤백함.
DBMS는 트랜잭션에 대한 완전 고립성을 제공하지만 응용 프로그램의 요구에 따라서는 완화된 트랜잭션 고립성을 제공함.
약한 일치성을 제공함에 따라 완전한 고립도가 요구되지 않을 수 있고, 이는 일치성보다는 시스템 성능을 더 중요하기 때문임.
(ex) 전국 남녀비율을 구하고자 함. 이때는 몇개의 데이터는 누락되어도 큰 문제가 되지 않기에 일치성을 줄이는 대신 성능을 높여서 빠르게 구할 수 있음.)
2단계 일치성
: 2PL과 달리 Read Lock을 제한없이 아무때나 해제할 수 있고(직렬가능이 보장되지 않음.) Write Lock은 여전히 트랜잭션이 끝날 때까지 잡고 있어야 함.
2단계 일치성에서 쓰는 방식 중 하나가 커서안정 방식인데 DB 커서가 위치하는 동안에만 Read Lock을 잡고 있는 방식임.
커서가 위치한 데이터는 타 트랜잭션에서 변경 불가하여 유저레게 데이터가 안정되어 보임.
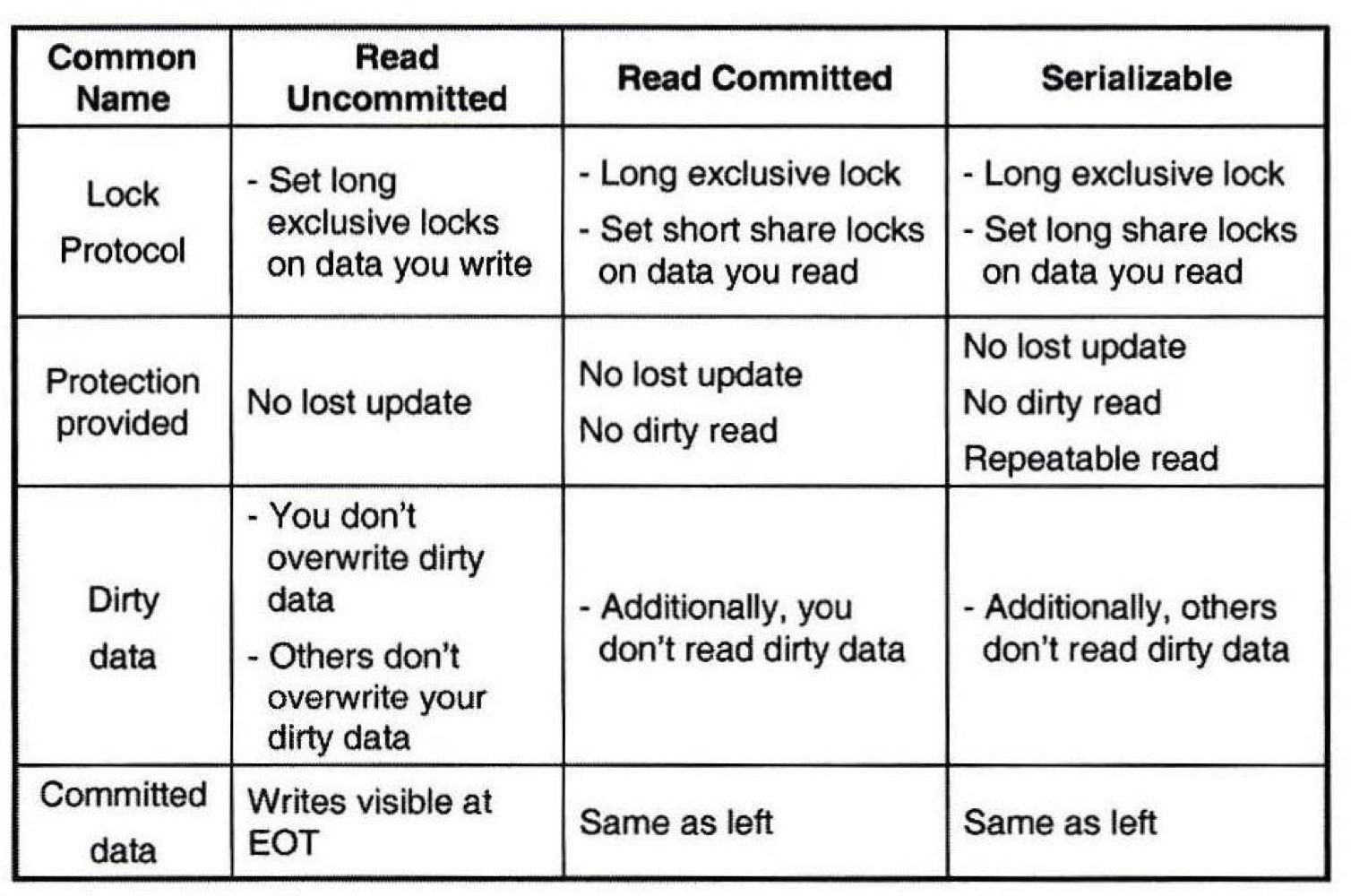
SQL 시스템의 4가지 형태의 실행 방식
1) Serializable - 직렬가능
2) repeatable read - 직렬가능X
: 팬텀 현상이 발생하기는 함.
3) read committed - 직렬가능X
: 2단계 일치성(커서 안정 방식)과 같음.
4) read uncommitted - 직렬가능X
: read 시에 lock 자체를 아예 잡지 않고 진행
비행기 예약 트랜잭션에서의 고립 예시
read uncommitted: read 연산 시 lock을 잡지 않기 때문에 읽은 데이터에 신뢰도가 없음. 만석이라 생각해도 만석이 아닐 수 있고 자리가 있다고 판단해도 자리가 없을 수 있음.
read committed: lock을 잡고 read 후 풀고 write를 하려는 사이에 다른 트랜잭션이 값을 변경하면 그 자리를 차지 못할 수도 있음.
repeatable read: 한번 읽은 값은 트랜잭션 끝까지 유지되기에 유저가 승인 후 실제 값을 변경 가능. 하지만 새로 생기는 자리나 제거되는 자리에 대해서 트랜잭션이 인지하지 못할 수 있음.
'대학 전공 공부 > 데이터베이스2' 카테고리의 다른 글
| 3장 연습문제 (0) | 2022.10.25 |
|---|---|
| 1장 연습문제 (0) | 2022.10.25 |
| 4. 저장 장치(Storage Devices) (0) | 2022.10.24 |
| 3. Recovery(복구) (2) | 2022.10.23 |
| 1. 트랜잭션 이론 및 회복가능(Recoverable) (0) | 2022.10.03 |


