
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 애플 디벨로퍼 아카데미 후기
- swift문법
- iOS 개발 오류
- 앱 비교 프로젝트
- 운영체제
- 제앱소
- react
- 개발회고
- 신입 개발자
- 신입ios개발자회고
- ios개발자
- SWIFT
- Apple Developer Academy @ POSTECH
- 개발자 회고
- 애플 디벨로퍼 아카데미
- 소프트웨어분석및설계
- 신입 ios 개발자
- 애플 아카데미 후기
- Swift 기능
- 데이터베이스
- Swift 문법
- sqoop
- OS
- 네이버 부스트캠프
- 애플 디벨로퍼 아카데미 21주차 회고
- Swift 디자인패턴
- global soop
- 네이버 치지직
- 숭실대
- apple developer academy 후기
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 애플 디벨로퍼 아카데미 후기
- swift문법
- iOS 개발 오류
- 앱 비교 프로젝트
- 운영체제
- 제앱소
- react
- 개발회고
- 신입 개발자
- 신입ios개발자회고
- ios개발자
- SWIFT
- Apple Developer Academy @ POSTECH
- 개발자 회고
- 애플 디벨로퍼 아카데미
- 소프트웨어분석및설계
- 신입 ios 개발자
- 애플 아카데미 후기
- Swift 기능
- 데이터베이스
- Swift 문법
- sqoop
- OS
- 네이버 부스트캠프
- 애플 디벨로퍼 아카데미 21주차 회고
- Swift 디자인패턴
- global soop
- 네이버 치지직
- 숭실대
- apple developer academy 후기
- Today
- Total
사과하는 제라스
11. Memory Management-1 본문
목차
범용 컴퓨터 시스템의 목적(=운영체제의 목적)
- CPU의 활용률을 극대화시킴.
- 사용자에게 빠른 응답을 제공함.
이러다 보니...!!
메모리 관리의 필요성 등장
- 여러 프로그램이 동시에 메모리에 적재되어 실행됨 -> "메모리 공유가 필요함!"
- 컴퓨터의 메모리는 한정적인 자원이다보니 관리가 필요 -> "자원이 한정적!"
Address Space(주소 공간)
: 프로세스에서 참조할 수 있는 주소들의 범위 및 집합
- 프로세스와 1:1 관계
- User Thread는 주소 공간을 공유함.
주소 공간의 크기
- CPU의 주소 버스의 크기에 의존함.
ex. 주소 버스가 32bit이면 2^32개의 서로 다른 주소에 대한 식별자를 만들 수 있기에,
0~2^32-1까지의 주소 범위를 Addressing할 수 있음.
예시 문제) 만약 32 bit 주소 버스를 가진 시스템이 주소 1개당 1Byte의 메모리를 접근할 수 있다면, 이 시스템이 Address할 수 있는 주소 공간의 크기는 ...? 2^32 * 1Byte = 2^32Byte
물리 주소 VS 가상 주소
물리 주소(PA, Physical Address)
: 컴퓨터의 메인 메모리를 접근 시 사용되는 주소. 기억 장치의 주소 레지스터에 적재되는 주소.
가상 주소(VA, Virtual Address, Logical Address)
: 프로세스의 관점에서 사용하는 주소.
- CPU 관점의 주소는 물리 주소도, 가상 주소도 될 수 있음.
- Logical하기 때문에 주소 공간을 의미 있는 단위로 나누어 사용X.
초창기엔 주소 관리 어케했을까...??
물리 주소를 Compile Time에 생성
: 컴파일러는 프로세스가 물리 메모리에서 실행되는 주소를 컴파일 타임에 알아서 절대 코드를 생성함.
∴ 시작 주소 위치가 변경될 시 다시 컴파일 해야 함.
근데...!!!
다양한 프로그램들이 실행되면서 컴파일 타임에 물리 주소 정하기 HARD!!
: 멀티 프로그래밍의 경우, 컴파일 타임에 결정된 주소는 다른 프로그램과 동시에 메모리에 로드하기 어려움. 혹은 메모리 부족 시 로드 불가능함.
-> 가상 주소를 생성하기 시작함.

각 Time 별 주소 결정
1) Compile Time
- 컴파일러가 Symbol Table(변수의 이름과 데이터의 주소를 저장하는 테이블)을 만들고 주소는 Symbol Table Relative(Symbol Table로부터 얼마나 떨어졌는지를 기준)한 주소로 이루어짐.
- 컴파일된 Object 파일은 주소 0부터 시작함(Relocatable)
-> Object 파일 생성
2) Link Time
- Object 파일들과 시스템에서 제공하는 라이브러리들을 묶어서 Symbol Table에 의존적이지 않은 주소 만듦.
- 링킹된 Executable 파일은 주소 0부터 시작함(Relocatable)
3) Load Time(로딩 시 물리 주소에 대한 바인딩이 일어난다.)
- 이 단계부터 PM을 함께 고려해야함.
- 프로그램의 실행을 위해 Loader는 Executable을 메모리로 load. 이때 VM이 어떤 PM과 연결될 지 Binding함. (시작 주소를 바꾸려면 다시 Load해야함)
- 이전에 생성한 프로그램이 Relocatable주소로 되어 있기 때문에 Base register를 통해 물리 주소로 바뀐다.
4) Execution Time
- 프로세스가 실행될 때 물리 주소가 바뀌는 경우 즉, Paging, Swapping에 의해 프로세스가 올려지는 메모리의 물리 주소가 바뀔 경우, 이때 물리 주소에 대한 Binding이 Process가 실행될 때 일어남.
- 이러한 방식의 구현을 위해 MMU와 같은 특별한 HW가 필요함.
- 현대의 대부분 운영체제가 이렇게 작동함.
아 개 어려운데...? 정리하자.
Address Space라는 것이 있다. 이는 Virtual Address Space, Physical Address Space로 따로 나뉜다.
최근의 OS들은 PA를 각 프로세스에 고정적으로 사용하지 않고 바뀐다.
CPU 위에서 프로세스가 실행될 때 이 프로세스가 지닌 주소들을 가지고 PA에 어케 접근함?
ARABOZA!
CPU에서 사용하는 주소에 따른 변환 방법
1) CPU에서 Physical Relative Address를 사용하는 경우
CPU가 프로세스의 VM에서 346번지를 접근하고자 함 -> MMU에게 찾아달라고 시작 주소(346번지)를 보내주면 MMU는 14000(상대적인 offset, 상대 주소)을 더해서 실제 물리메모리의 14346번지(절대 주소)를 가서 메모리 값을 찾아다가 CPU에게 넘겨줌.

이 방식은 PA가 바뀌면 안되는데 요즘 방식은 메모리를 효율적으로 쓰기 위해 PA가 변하는 방식을 씀.
2) CPU에서 Virtual Address를 사용하는 경우
CPU가 VA를 물어오면 MMU의 Translation이 PA로 바꿈. 이때 동일한 VA 값에 대해 PA 값은 달라질 수 있음.
(이때 Translation의 속도가 메모리 효율 면에서 중요한 요소가 되었다.)

MMU(Memory Management Unit)
: VA와 PA 간의 변환을 수행하는 HW 장치

가상 메모리
: 실제 존재하진 않는 메모리지만, 사용자에게 메모리로서의 역할을 하는 메모리.
-> 현재 실행되고 있는 Code 부분만이 실제 메모리에 있으면 프로세스 실행이 가능하기에~

가상 메모리의 구현
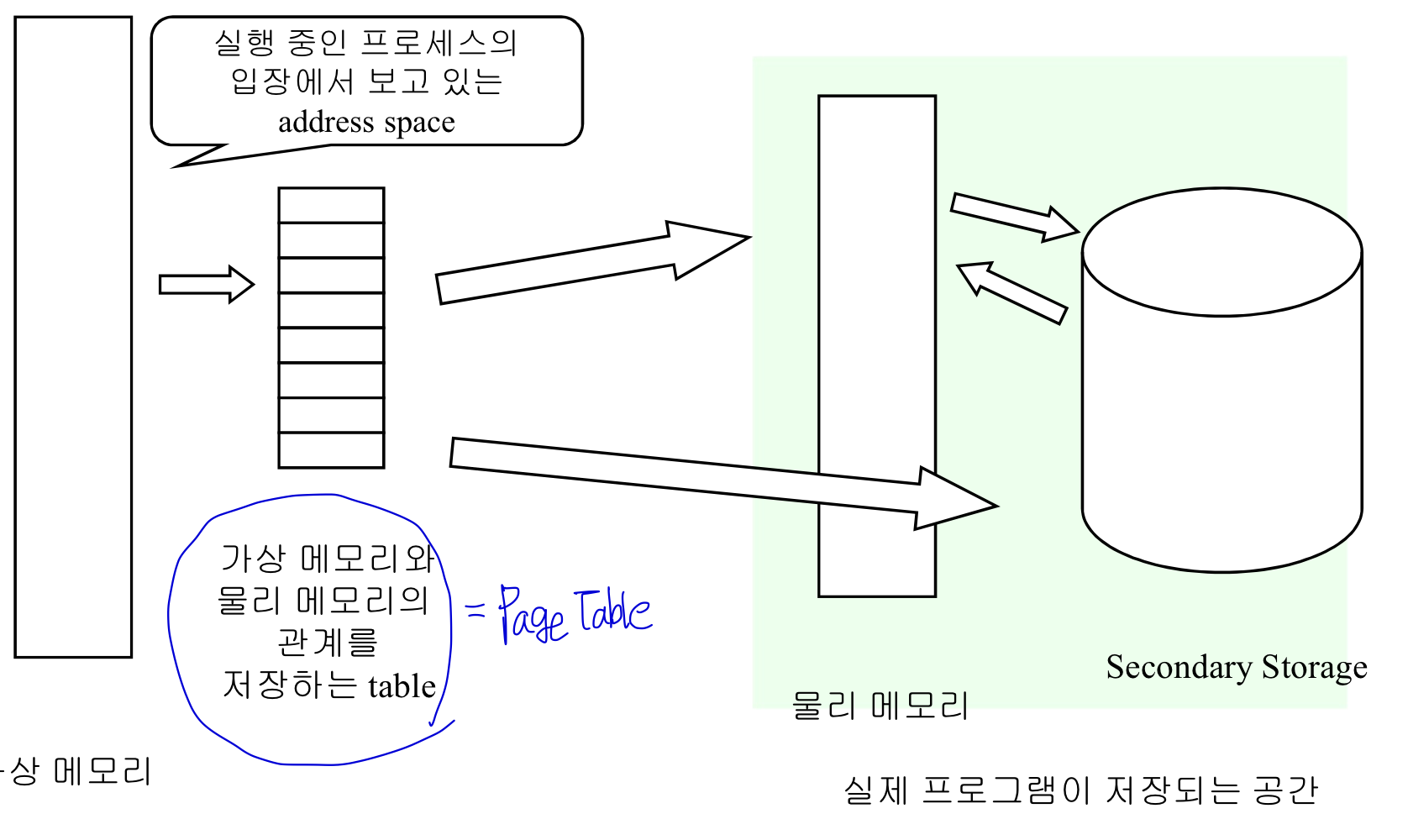
가상 메모리의 Address Mapping Table

Paging
: 주소 공간을 동일한 크기인 Page로 나누어 관리하는 방법.
- 보통 1 Page = 1KB임.
- Page: VM을 고정된 크기로 나누었을 때, 하나의 Block
- Frame: PM을 고정된 크기로 나누었을 때, 하나의 Block
- 각 Page와 Frame의 크기는 동일함.
Page가 하나의 Frame을 할당받으면, 물리 메모리에 위치하게 됨.
- 만약 할당받지 못하면 외부 저장장치(Backing Storage)에 저장되는데 거기도 Page(=Frame) 크기로 나뉘어져 있음.
CPU가 관리하는 모든 주소는 두 부분으로 나뉨.
- Page 번호: 각 프로세스가 가진 Page 각각에 부여된 번호
- Page 주소: 각 Page의 내부 주소 ex)1번 프로세스 12번 페이지의 34번째 Data
Page Table
- 각 프로세스마다 하나의 독립된 Page Table을 가짐
- index: Page 번호
- 내용: 해당 Page에 할당된 물리 메모리의 시작 주소
-> 이 시작 주소 + Page 주소를 결합하여 원하는 데이터의 물리 메모리 주소를 알 수 있음.
Page Talbe의 구현(중요)
- Page Table은 물리 메모리에 위치함.
- Page Table Base Register(PTBR)가 물리 메모리 내의 Page Table을 가리킴.
Page Table을 이용한 주소 변환

VA는 두가지 부분으로 구성됨.
앞 부분 - Page Table Entry를 찾는데에 쓰임.
뒷 부분 - 물리 메모리에서의 page 안에 있는 데이터를 찾는데에 쓰임.
Page Table Entry(PTE)
: Page Table의 Record
PTE의 각 필드 내용
- Page Base Address
: 해당 Page에 할당된 Frame의 시작 주소
-> 이걸로 물리 메모리 접근 가능.
- Flag Bits
1) Accessed Bit: 해당 Page에 대한 접근이 있었는지 여부
2) Dirty Bit: Page 내용의 변경이 있었는지 여부
3) Present Bit: 현재 해당 Page에 할당된 Frame이 있는지 여부
4) Read/Write Bit: 읽기/쓰기에 대한 권한 표시
등등
Translation Look-aside Buffer
- Paging 방법에서는 Data로의 접근이 항상 2번(Page Table, 물리 메모리 내에서 각각 1번씩)의 메모리 접근을 거쳐야 함.
-> 이거 해결 방법이 바로 MMU의 'TLB'
: Page Table을 이용해서 변환된 주소를 TLB에 저장해 둠 -> 다음 접근 시 저장된 값으로 빠르게 변환된 주소를 얻음
(TLB는 Register이기에 빠른 수행이 가능함.)
- TLB Hit Ratio
: TLB 내에 원하는 주소가 등록되어 있을 확률()
-> 이 값이 높을 수록 접근 속도를 향상시킬 수 있음.

Multilevel Page Table
이전까진 배운 건 Page Table 한개짜리임. 근데 시스템이 복잡해짐, VAS도 커짐, 그 결과 Page Table이 커짐.
-> 근데 Page Table이 커지면 사용가능한 물리 메모리 공간이 줄어듦.
ex. 32bit 가상 주소 공간을 가지는 시스템
-> Page 크기가 4KB(2^12bit)라 하면, PageTable 크기는 1M(2^(32-12))*4B = 4MB임.
이거 해결하기 위해...등장한 게...!!
여러 Page Table을 갖는 '다단계 Page Table'
2 Level Page Table
: Outer Page Table을 하나 더 둬서 Page Table들을 가리킴.
ex. 위의 예시에서 20bit를 차지하는 Page 번호를 다시 나눔.



(2 Level Page Table을 깊게는 공부 안해도 됨.)
근데 이렇게 Page Table 단계가 늘어나면 Memory가 줄어들긴 하지만... Table Walk에 걸리는 시간이 증가함.
예를 들면, 64bit 주소 공간의 시스템에서 Multilevel Paging을 위한 정보의 크기는 2^32배...!!
- 이게 아무리 VM이 공간이 크더라도 PM의 크기에는 한계가 있음.
+ 모든 PM은 VM의 Page에 Mapping될 확률이 높네...!!??
그래서 나온 아이디어가...!!!
Inverted Page Table

- 기존 방식: 찾고자 하는 Page의 번호를 받아오면 그에 맞는 PM(Frame)을 찾아오는 방식.
- Inverted Page Table: 각 프레임들에 대해 PID와 Page #이 할당되어 있기에 Page Table에서 프로세스 ID와 접근하고자 하는 는 Page 번호를 쌍으로 비교하고 찾아지면 그것이 연결되어 있는 PM(Frame)을 찾아옴.
구현
1) System 전체에 하나의 Page Table만 둔다.
2) Page Table의 구성 -> Page Table index: Frame 검색해서 ㄱㄷ번호 / Page Table 내용: PID + Page 번호, Page 주소
ex. 12번 프로세스의 23번 페이지의 34번째 데이터를 찾고자 함.
-> Page Table에서 12,23으로 이뤄진 index를 찾음 - 해당 index의 Frame에서 34번째 데이터에 접근함.
이런 방식의 Inverted Page Table은 적은 용량을 차지하지만, Table을 검색하는데에는 시간이 오래 걸림.
(사실 이거 해쉬 테이블 등을 사용하면 단축이 가능.)

Demand Paging
: 프로세스의 실행을 위한 모든 Page를 메모리에 올리지 않고, 필요한 Page의 요청이 발생 시 메모리에 올리는 Paging 기법
-> Paging Service를 통해서 한 프로세스에 필요한 Page를 메모리와 Secondary Storage 간에 이동시킴.
(필요한 Page들만을 Memory에 올려놓고 불필요한 Page들은 Secondary Storage에 저장해둠.)
Demand Paging을 사용하기 위해서는 Valid Page / Invalid Page 개념이 필요.
Valid Page: 현재 PM에 올라와 있는 Page
Invalid Page: 메모리에 올라와 있지 않고 Secondary Storage에 저장되어 있는 Page
이것들 통해서 뭐가 좋은데...!!!!!???
1) 실행을 위한 PM 구성의 시간이 줄어듦.
2) 프로세스의 전체 이미지를 메모리에 올리지 않아도 되기에 실제 필요한 전체 PM의 양을 줄일 수 있음.
단점도 있나...??ㅠㅠ
참조하려는 Page가 Valid하면 실제 PM에 있기에 정상적인 참조 발생.
-> 하지만 Invalid한 경우엔 실제 PM에 없기에 이에 대한 처리가 필요함 (= Page fault 발생함.)
Demand Paging을 하기 위해서는 Page Table에 어떠한 정보가 더 필요함?
= Valid-Invalid bit가 필요함.

Page Fault
Page Fault는 프로세스가 Page를 참조하였을 때 해당 Page가 할당 받은 Frame이 없는 경우 발생함.
1) 있는 경우(현재 bit == valid)
-> Page base address를 통해 해당 Frame에 접근함.
2) 없는 경우(현재 bit == invalid)
-> Page Fault가 발생함. 즉, Frame을 새로 할당받아야 함.
∴ Page Fault Handler를 수행함.
Page Fault Handler가 수행하는 내용
새로운 Frame을 할당받음 - Backing Storage(= Secondary Storage)에서 Page의 내용을 다시 Frame에 불러들임
- Page Table을 재구성함 - 프로세스의 작업을 재시작함.

1) 메모리에 접근하려고 Page Table로 감. 어? 근데 Invalid해서 Page Fault가 발생함.
2) trap이 발생함(동기적 이벤트임. 프로세스가 발생시키는 것이니까~~)
정보) trap: 어떤 프로세스가 특정 시스템 기능을 사용하려고 할 때 그 기능을 운영체제에게 요청하는 방법.
3) OS는 이 요청을 받아서 Page Fault Handler 실행되어(이때, 프로세스는 멈춰야 함.) Storage에 있는 Page를 찾아서 새로 할당한 Frame에 로딩함.
4) 이후, 해당 Frame에 대해서 Page Table을 update함.
5) 이후, 프로세스의 작업을 재시작함.

-> 이를 고려하여 나온 Page(Frame)의 크기가 4KB임.
Locality

실험을 통해 Page Fault는 특정 시간대에 사용하는 Page가 집중되어 있음을 알 수 있다.
-> Page Fault는 Locality한 특성을 갖는다는 것을 알게됨.
근데, VOD를 트는 경우
-> 시간을 지날수록 계속 새로운 데이터들이 로딩됨. 이런 특이한 경우도 있음.
Working Set
: 특정 프로세스가 특정 시간동안 접근해서 사용한 메모리의 Page 집합.
이런 Working Set은 시간마다 변함.
∴ 적당한 시간대 구역을 잡아서 보면 Working Set은 Locality를 나타냄.
Thrashing
: 프로세스 실행 중에 Page Faul 처리에 걸린 시간이 실행 시간보다 긴 상황
'대학 전공 공부 > 운영체제' 카테고리의 다른 글
| 13. File System (0) | 2022.12.09 |
|---|---|
| 12. Memory Management-2 (1) | 2022.12.08 |
| 10. Synchronization(동기화)-2 (3) | 2022.12.01 |
| 9. Synchronization(동기화)-1 (0) | 2022.11.24 |
| 8. Thread (2) | 2022.11.19 |



