
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 제앱소
- 앱 비교 프로젝트
- 신입 개발자
- 신입ios개발자회고
- global soop
- 운영체제
- 숭실대
- 애플 아카데미 후기
- Swift 문법
- swift문법
- sqoop
- 신입 ios 개발자
- Swift 디자인패턴
- SWIFT
- Swift 기능
- 개발회고
- 네이버 치지직
- 애플 디벨로퍼 아카데미 21주차 회고
- ios개발자
- 소프트웨어분석및설계
- OS
- Apple Developer Academy @ POSTECH
- apple developer academy 후기
- react
- 개발자 회고
- 데이터베이스
- 애플 디벨로퍼 아카데미 후기
- 네이버 부스트캠프
- 애플 디벨로퍼 아카데미
- iOS 개발 오류
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 제앱소
- 앱 비교 프로젝트
- 신입 개발자
- 신입ios개발자회고
- global soop
- 운영체제
- 숭실대
- 애플 아카데미 후기
- Swift 문법
- swift문법
- sqoop
- 신입 ios 개발자
- Swift 디자인패턴
- SWIFT
- Swift 기능
- 개발회고
- 네이버 치지직
- 애플 디벨로퍼 아카데미 21주차 회고
- ios개발자
- 소프트웨어분석및설계
- OS
- Apple Developer Academy @ POSTECH
- apple developer academy 후기
- react
- 개발자 회고
- 데이터베이스
- 애플 디벨로퍼 아카데미 후기
- 네이버 부스트캠프
- 애플 디벨로퍼 아카데미
- iOS 개발 오류
- Today
- Total
사과하는 제라스
13. File System 본문
목차
File이란?
: Array of Bytes
: A Collection of Related Information
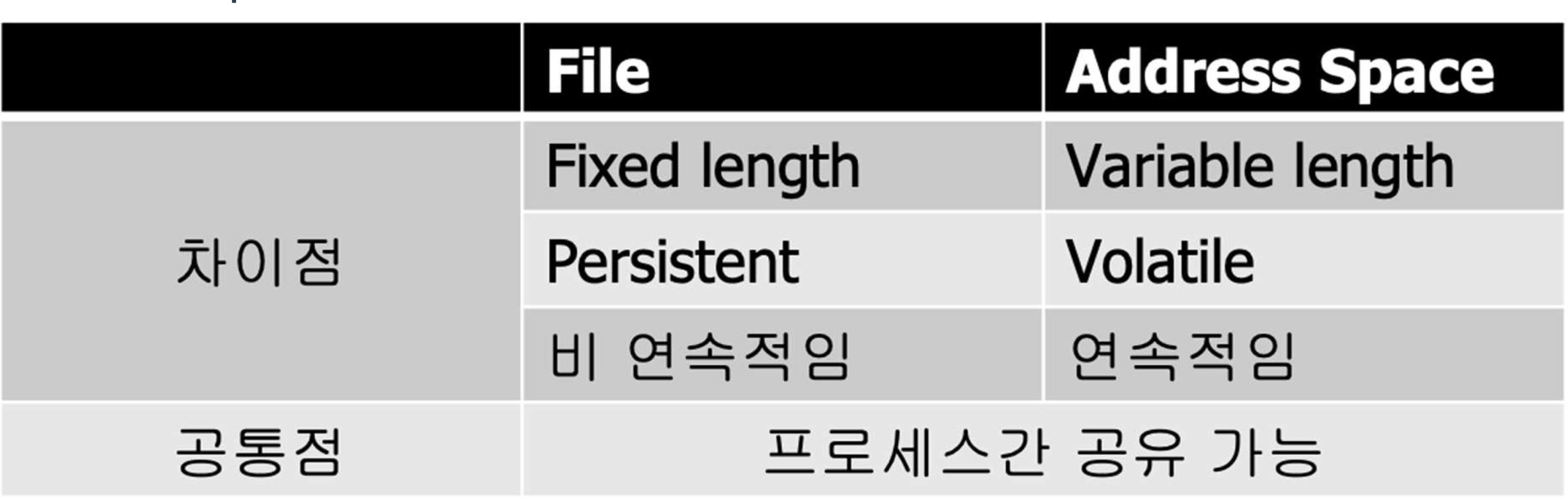
File System
-> Memory Management System과 유사한 일을 함.
1) File과 Physical Disk Block 간의 Mapping을 제공함.
- Disk 위치 배치를 담당함(File Blocks -> Disk Blocks)
∴ 유저는 File이 저장된 위치를 알 필요가 없음.
2) Disk에 들어가 있는 File 전체를 총칭함.
-> File System의 종류에 따라 File들의 배치나 구성이 달라질 수 있음.

File Operations

Open / Close Semantics
여러 프로세스가 파일을 공유하는 경우,
두개의 Open File Table을 유지함.
1) Per Process Table: 각 프로세스에서 유지하는 State를 가짐
ex. File Pointer
2) System-Wide Table: Process Independent Information으로 시스템 전역에서 사용 중인 Table임.
ex. Access Date, File Location, Open Count
-> 예를 들어, Open Count를 보자!
File을 Open하면 Open Count를 1 증가시키고, Close하면 1 감소시킴.
이때, Delete 동작은 System-wide Table에서 Open Count를 확인하고 0일 때만 이루어질 수 있음.
File Access Method
1) 순차 접근
: 옛날 방식임. File에 있는 정보에 대한 접근이 Record의 순서대로 이루어짐.
그래서 가능한 Operation들이
Read Next(다음을 읽어라) / Write Next(다음에 써라) / Reset(다시 처음 Record로 돌아가라)
이게 다임.

2) 임의 접근
: 요즘은 파일의 어떤 위치에 있더라도 바로 접근함. File의 어떠한 위치라도 바로 접근하여 Read/Write를 수행함.
가능한 Operation들이
Read n(n 위치에 있는 것을 읽어라) / Write n(n 위치에 적어라)
임.
File System의 구성
File System의 계층화
File System은 일반적으로 여러 개의 계층으로 나뉘어져 구성됨

왜 계층을 나눌까...??
1) File System을 구현하고자 하는 장치가 다양할 수 있음.(한 컴퓨터 안에 다양한 물리 장치들이 사용하기 때문)
2) 한 System에 여러 개의 File System을 사용 가능하게 함.
3) 계층화된 구성을 통해 File System에 유연성을 제공함.(필요 기능에 맞게 따로따로 사용할 수 있게 함.)
Mount
: File System을 특정 Diretory에 붙이는 개념
파일을 사용하려면 -> Open
파일 시스템을 사용하려면(접근하고자 하는 물리적인 데이터가 물리 장치에 저장되어 있고 이에 접근하고자 한다면) -> Mount
Mount를 하면 Mount를 한 폴더를 통해 장치에 저장된 물리 데이터에 접근 할 수 있게 된다.
왜 Mount라는 개념이 사용되기 시작함?
-> 분산된 File System을 사용하면서 이들을 쉽고 편리하게 사용하기 위해서
Mount 과정

-> 아래 그림처럼 usr를 통해 Disk2로 접근하는 것처럼 보이지만 실제로는 그렇지 않음.
즉, '나뉘어진' File System을 하나의 시스템에서 유연하게 사용함.(하나의 디스크인 것처럼 사용!)
Directory Structure
: 모든 File들에 대한 정보를 가지는 Node들의 집합.
- Directory Structure와 File은 모두 Disk 상에 있음.
그렇다면 Directory Structure는 어떻게 발전해왔을까???????

근데, Two-level 디렉토리도 user마다 나누긴 했지만 user마다 single-level 디렉토리가 되었으니 파일이 증가할수록 디렉토리가 무수히 늘어날 수 밖에 없었음. 그래서 나온게...!!

좀 더 유연한 형태의 Directory Structure를 가져보자해서 나온게...!!!
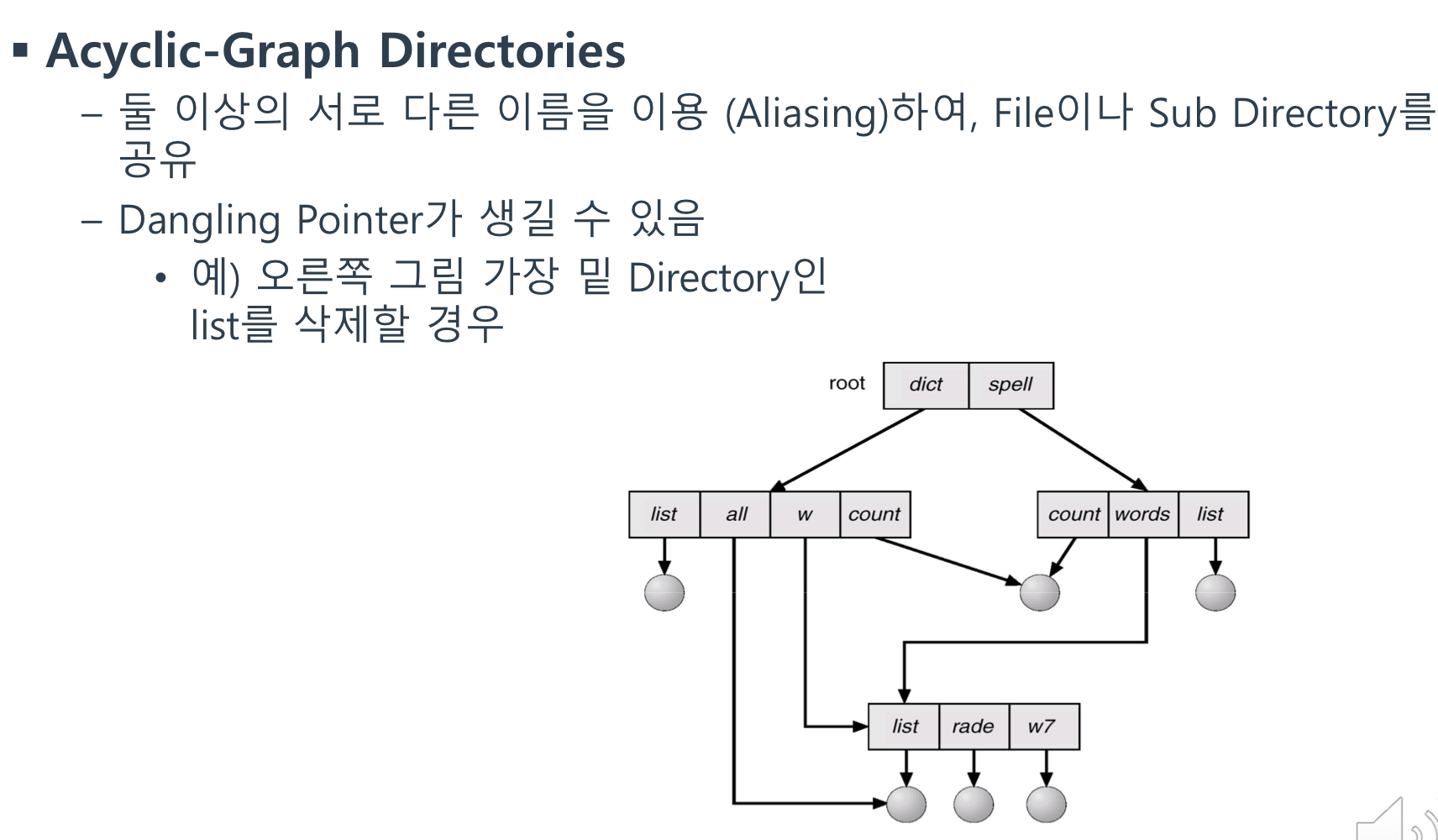
앞선 Tree-Structured Directory와 달리 같은 파일 or 디렉토리를 서로 다른 디렉토리에서 찾아갈 수 있음.
근데, 문제점...!!!!
Dangling Pointer
-> list에서 그 안의 파일을 지우면 list는 삭제되지만 'all' 디렉토리는 아무것도 가리키지 않은 채 남겨진 Dangling Pointer가 되어버림.
이런 Dangling Pointer 관리가 중요했었다잉~~ 이정도만 알아두자

Cycle 형태를 지원을 해주는 그래프임.
∴ 이런 싸이클을 없도록 하기 위해
1) Link를 File로만 가능하게 함.
2) 매번 Link 연결 시 Cycle Detection Algorithm으로 검사함.
-> 이를 통해 Cycle 없도록 보장
File 구현
디스크는 PM의 Frame처럼 일정 Block 단위로 나뉘어져 있고 이 Block은 File System의 입출력 단위가 된다.
이것을 Disk Block이라고 한다.
File의 데이터를 실제로 저장하는 이 Disk block의 위치 정보를 어떻게 저장할지가 File 구현에 중요한 요소이다. OS마다 서로 다른 방식으로 File의 Data block 정보를 관리하는데 사실 현재는 I-Node를 대부분 사용한다.
Contiguous Allocation
: File을 물리적으로 연속된 Disk Block에 저장함.
- 장점
1) 구현이 간단함
2) 물리적으로 연속된 공간에 있기에, 전체 File을 한번에 읽어들일 때 성능이 매우 뛰어남.
- 단점
1) File은 반드시 한번에 끝까지 기록되어야 함.
2) OS에서 File의 끝에 예비용 Block을 남겨둘 경우, Disk의 공간을 낭비함.

이런 공간 낭비를 보완하기 위해 나온게...!!!!!!!
Linked List Allocation
: Disk의 Block을 Linked List로 구현하여, File의 Data를 저장하도록 함.
- 장점
1) File의 Data Block은 Disk의 어디든지 위치 가능함.
2) 공간의 낭비가 없음
- 단점
1) Random Access가 불가능함.
즉, File의 특정 위치를 찾기 위해서는 해당 File의 시작 Node부터 찾아가야 함.
2) 다음 Data Block에 대한 Pointer로 인해, Data Block에서 Data를 저장하는 공간이 반드시 2의 배수가 아닐 수도 있음.
즉, 대부분의 프로그램은 Read/Write하는 Data의 크기가 2의 n승이기에 성능 면에서 뒤쳐짐.

Linked List Allocation using an Index
: File의 Data에 관련된 Block을 하나의 Block에 모아 둠.
(File의 Data Block 중 하나를 Index Block이라 하여, 모든 Data Block의 위치를 Index Block에서 알 수 있음)
- 개선된 점
-> Random Access 시, 하나의 Data Block에서 찾아가고자 하는 Data Block의 위치를 알 수 있기에 빠른 접근 가능함.
- 단점
: 최대 File의 크기가 고정됨
∵ Index Block의 크기가 고정되어 있기에 Index Block에서 수용 가능한 Data Block에 대한 Pointer 수가 한정됨.

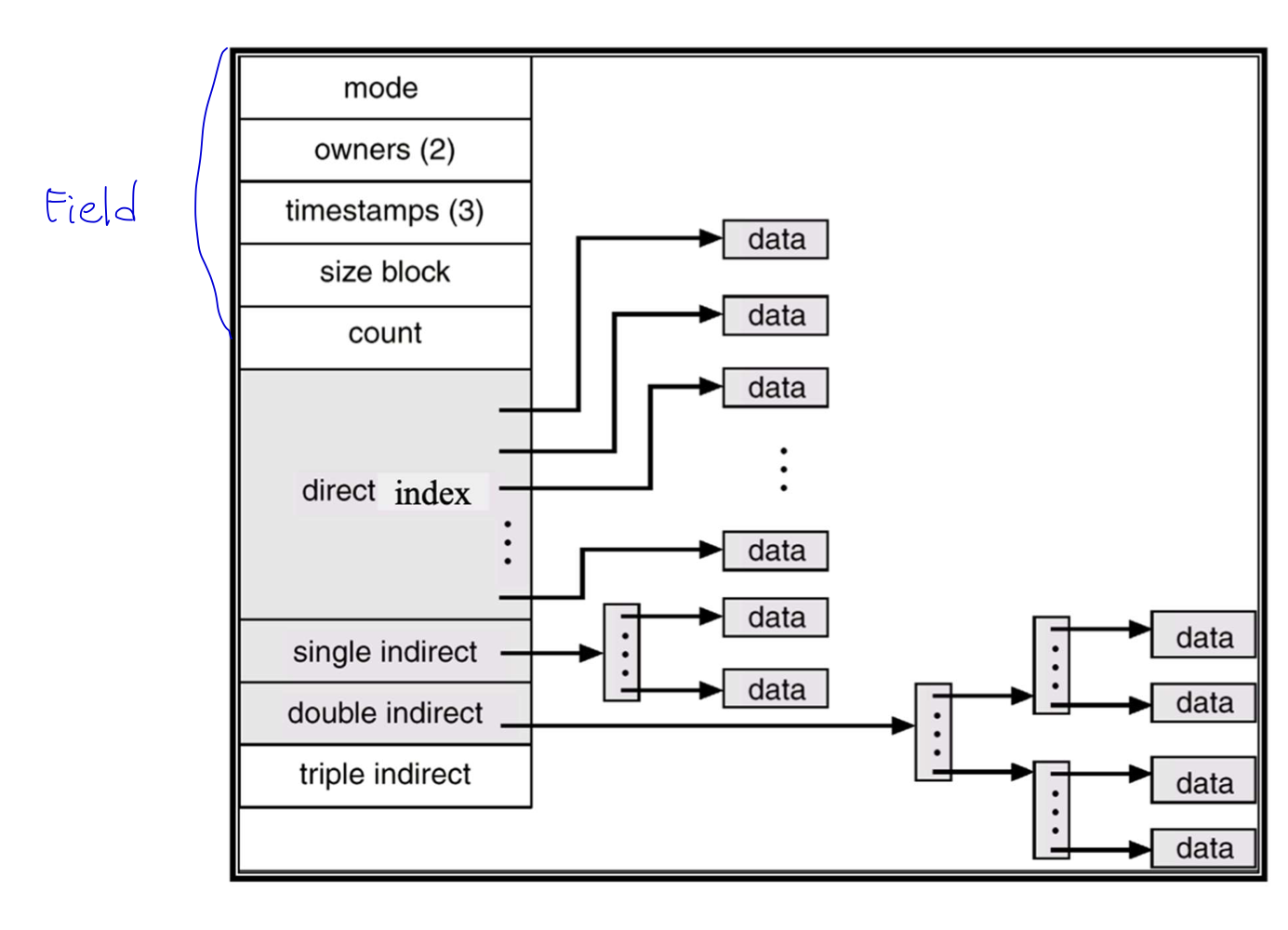
I-nodes
: File에 대한 Data Block Index들을 Table 형태로 관리하는 방법
- 구성요소
1) File에 대한 속성을 나타내는 Field
2) 작은 크기의 File을 위한 Direct Index
3) File의 크기가 커짐에 따라 요구되는 Data Block의 Index들을 저장하기 위한 Index Table들
- Single Indirect Block
- Double Indirect Block
- Triple Indirect Block
Directory 구현
Directory entry: 디렉토리를 표현하기 위한 자료구조
이 자료구조는 데이터를 저장하는 방식(File System의 File 구현)에 따라 달라짐.
- MS-DOS(Linked list allocation)
- UNIX(I-node)
MS-DOS(Linked list allocation)
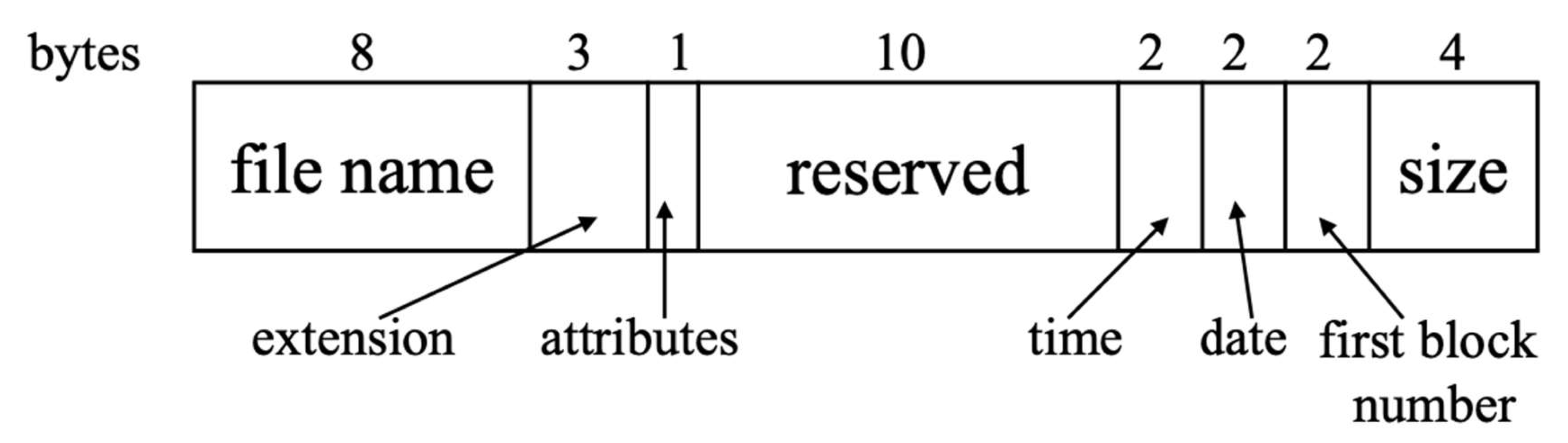
- File마다 이런 Directory Entry로 구성됨.
- 첫 Block의 number를 통해 실제 File의 Data Block이 시작되는 Block을 알 수 있음.
-> 포인터로 나머지 block들(전체 File의 Data)에 접근 가능함.
UNIX(I-node)

- Directory Entry가 File 이름+ I-node 번호로 이루어짐.
- attribute, ownership 등과 같은 정보들은 File의 I-node 자료구조에 직접 저장되어 있음.
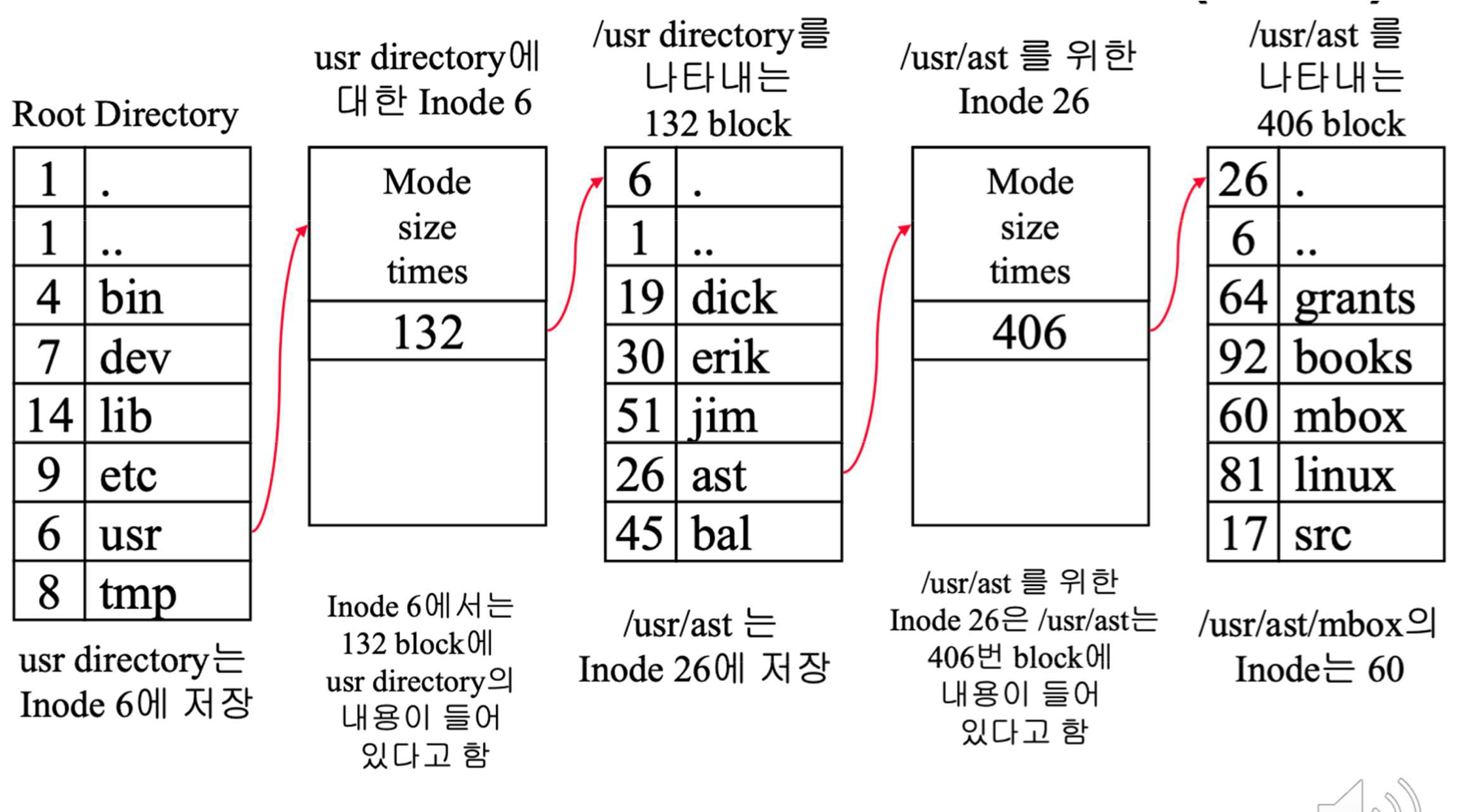
- 디렉토리의 정보도 파일로써 관리됨.
Protection
: 파일에 대한 부적절한 사용이나 접근을 막는 것
Access Type에는 다음과 같은 것들이 있음.
- Read
- Write
- Execute
- Append
- Delete
- List: File의 속성이나 이름의 내용

'대학 전공 공부 > 운영체제' 카테고리의 다른 글
| 12. Memory Management-2 (1) | 2022.12.08 |
|---|---|
| 11. Memory Management-1 (1) | 2022.12.06 |
| 10. Synchronization(동기화)-2 (3) | 2022.12.01 |
| 9. Synchronization(동기화)-1 (0) | 2022.11.24 |
| 8. Thread (2) | 2022.11.19 |



